Abstract
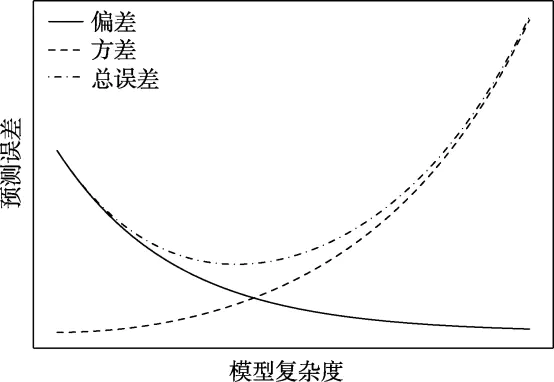
Cognitive modeling has gained widespread application in psychological research, providing a robust framework for understanding complex cognitive processes. These models are instrumental in elucidating how mental functions such as memory, attention, and decision-making work. A critical aspect of cognitive modeling is model comparison, which involves selecting the most appropriate model for describing the behavior data and latent variable inference. The choice of the best model is crucial as it directly influences the validity and reliability of the research findings.Selecting the best-fitting model often requires careful consideration. Researchers must balance the fit of the models to the data, ensuring that they avoid both overfitting and underfitting. Overfitting occurs when a model describes random error or noise instead of the underlying data structure, while underfitting happens when a model is too simplistic and fails to capture the data’s complexity. Additionally, researchers must evaluate the complexity of the parameter data and the mathematical forms involved. This complexity can affect the model’s interpretability and the ease with which it can be applied to new data sets.This article categorizes and introduces three major classes of model comparison metrics commonly used in cognitive modeling goodness-of-fit metrics, cross-validation-based metrics, and marginal likelihood-based metrics. Each class of metrics offers distinct advantages and is suitable for different types of data and research questions.Goodness-of-fit metrics are straightforward and intuitive, providing a direct measure of how well a model fits the observed data. Examples include mean squared error (MSE), coefficient of determination (R2), and receiver operating characteristic (ROC) curves. Cross-validation-based metrics provide a robust means of assessing model performance by partitioning the data into training and testing sets. This approach helps mitigate the risk of overfitting, as the model’s performance is evaluated on unseen data. Common cross-validation metrics include the Akaike Information Criterion (AIC) and the Deviance Information Criterion (DIC). Marginal likelihood-based metrics are grounded in Bayesian statistics and offer a probabilistic measure of model fit. These metrics evaluate the probability of the observed data given the model, integrating over all possible parameter values. This integration accounts for model uncertainty and complexity, providing a comprehensive measure of model performance. The marginal likelihood can be challenging to compute directly, but various approximations, such as the Bayesian Information Criterion (BIC) and Laplace approximation, are available. The article delves into the computation methods and the pros and cons of each metric, providing practical implementations in R using data from the orthogonal Go/No-Go paradigm. This paradigm is commonly used in cognitive research to study motivation and reinforcement learning, making it an ideal example for illustrating model comparison techniques. By applying these metrics to real-world data, the article offers valuable insights into their practical utility and limitations. Based on this foundation, the article identifies suitable contexts for each metric, helping researchers choose the most appropriate method for their specific needs. For instance, goodness-of-fit metrics are ideal for initial model evaluation and exploratory analysis, while cross-validation-based metrics are more suitable for model selection in predictive modeling. Marginal likelihood-based metrics, with their Bayesian underpinnings, are particularly useful in confirmatory analysis and complex hierarchical models. The article also discusses new approaches such as model averaging, which combines multiple models to account for model uncertainty. Model averaging provides a weighted average of the predictions from different models, offering a more robust and reliable estimate than any single model. This approach can be particularly beneficial in complex cognitive modeling scenarios where multiple models may capture different aspects of the data. In summary, this article provides a comprehensive overview of model comparison metrics in cognitive modeling, highlighting their computation methods, advantages, and practical applications. By offering detailed guidance on choosing and implementing these metrics, the article aims to enhance the rigor and robustness of cognitive modeling research. Model comparison involves considering not only the fit of the models to the data (balancing overfitting and underfitting) but also the complexity of the parameter data and mathematical forms. This article categorizes and introduces three major classes of model comparison metrics commonly used in cognitive modeling, including goodness-of-fit metrics (such as mean squared error, coefficient of determination, and ROC curves), cross-validation-based metrics (such as AIC, DIC), and marginal likelihood-based metrics. The computation methods and pros and cons of each metric are discussed, along with practical implementations in R using data from the orthogonal Go/No-Go paradigm. Based on this foundation, the article identifies the suitable contexts for each metric and discusses new approaches such as model averaging in model comparison.